 Sampling the electorate
Sampling the electorateI was listening to NPR's Science Friday and heard Ira Flatow decry the confusing business of contradictory polls. He mentioned that there are polling firms that specialize in working for Republican candidates and others that are allied with Democrats. Where are the independent and neutral polls of yesteryear?
The discussion went off in other directions without doing more than the radio equivalent of hand-wringing over partisan pollsters. I would like to offer some constructive comments on the practice of polling and the significance of polling results. I hope this primer on polling will answer some of the questions you might have.
Any reader of Halfway There knows that I am myself a partisan Democrat, so you might suspect I'm going to shade this essay on polling to favor my preferred liberal causes. You can decide for yourself, of course, after reading what I have to say. In the interests of balance, however, let us begin with a comment from arch-conservative Phyllis Schlafly:
Dr. George Gallup began asking a lot of questions of a very few people, and—funny thing—he usually came up with the answers that pleased the New York kingmakers.Schlafly made this observation in the context of complaining how pollsters manipulate the electorate with statistically meaningless results that favor New Deal liberals. The quote comes from chapter 6 of Schlafly's 1964 book A Choice Not an Echo (there really ought to be some punctuation in there), which promoted the insurgent candidacy of Barry Goldwater for the Republican nomination for president.
Schlafly homes in on one of the most popular complaints about polls, often voiced by individuals who say, “No one has ever polled me!” Indeed, pollsters usually examine a sample that is much smaller than the actual population in question. For a statewide election in California, for example, a pollster is likely to interview a few hundred voters to discover the opinions of an electorate that comprises millions. How can this possibly work?
A sample example
A small sample can give you a surprisingly robust measure of what is going on with a large population. As long as the pollster takes some practical measures to ensure that a sample is not unduly skewed (don't find all your polling subjects in the waiting rooms of Lexus dealerships!), the sample will be representative of the whole population. That's why you'll hear people talk about picking people at random in a polling survey. It's a way to avoid biasing a sample.
Suppose, for the sake of illustration, that a voting population is evenly divided between candidates A and B. Suppose that you're going to pick two voters at random and ask them who they prefer. What could happen?
There are actually four possible outcomes: Both subjects prefer A, both subjects prefer B, the first subject prefers A while the second prefers B, and the first subject prefers B while the second prefers A. These four outcomes are equally likely, leading us to an interesting conclusion: Even a sample of size 2 gives you a correct measure of voter preference half the time!

No doubt this result should improve if we choose a larger sample. After all, while it's true that half of the possible outcomes correctly reflect the opinions of the electorate, the other half is way off, telling us there is unanimous sentiment in favor of one candidate.
Let's poll four voters this time. There are actually sixteen (24) equally likely results:

This time, six of the possible sample results (that's three-eighths) are exactly right in mirroring the fifty-fifty split of the electorate. What's more, only two of the possible samples (one-eighth of them) tell us to expect a unanimous vote for one of the candidates. The other samples (three-eighths of them) give skewed results—giving one candidate a three-to-one edge over the other—but not as badly skewed as in the previous two-person sample.
You know what's going to happen as we continue to increase the sample size: It's going to get more and more difficult to obtain really unrepresentative results. Let's look at what occurs when we increase the sample size to just eight randomly selected voters. There are 28 = 256 ways the samples can come up, varying from all for A to all for B. Okay, that's too many cases to write out individually. We'll have to group them. The following table summarizes the possibilities. For example, there are 28 cases in which we end up with 6 votes for A versus 2 for B. (In case you're curious, these numbers come from binomial coefficients, made famous in Pascal's triangle.) Check it out:
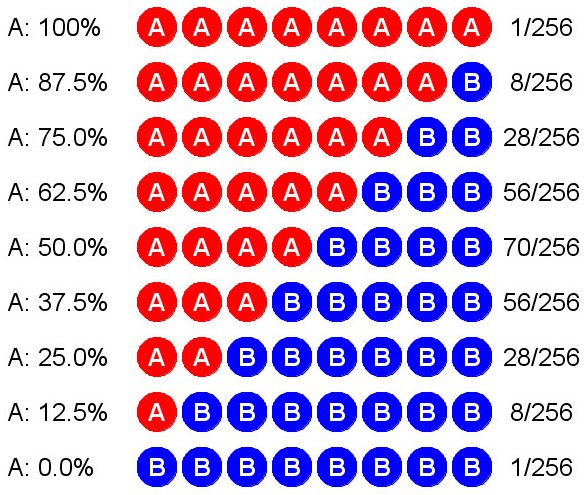 As you can see, in each case I've given the percentage of supporters for A found in the sample. There are 56 samples in which A has 62.5% support, 70 in which A has 50% support, and 56 in which A has only 37.5%. In this little experiment, therefore, we have 56 + 70 + 56 = 182 cases out of 256 in which A has support between 37.5% and 62.5%. Since 182/256 ≈ 71%, that is how often our random sample will indicate that A's support is between 37.5% and 62.5%. Observe that 37.5% = 50% − 12.5% and 62.5% = 50% + 12.5%. Since we set this up under the assumption that A's true support is 50%, our poll will be within ±12.5% of the true result about 71% of the time. Mind you, we have no idea in advance which type of sample we'll actually get when polling the electorate. We're playing the percentages, which is how it all works.
As you can see, in each case I've given the percentage of supporters for A found in the sample. There are 56 samples in which A has 62.5% support, 70 in which A has 50% support, and 56 in which A has only 37.5%. In this little experiment, therefore, we have 56 + 70 + 56 = 182 cases out of 256 in which A has support between 37.5% and 62.5%. Since 182/256 ≈ 71%, that is how often our random sample will indicate that A's support is between 37.5% and 62.5%. Observe that 37.5% = 50% − 12.5% and 62.5% = 50% + 12.5%. Since we set this up under the assumption that A's true support is 50%, our poll will be within ±12.5% of the true result about 71% of the time. Mind you, we have no idea in advance which type of sample we'll actually get when polling the electorate. We're playing the percentages, which is how it all works.These results are pretty crude, since professional polls do much better than ±12.5% only 71% of the time, but we did this by asking only eight voters! A real poll would ask a few hundred voters, which suffices to get a result within ±3% about 95% of the time. That's why pollsters don't have to ask a majority of the voters their preferences in order to get results that are quite accurate. A relatively small sample can produce a solid estimate.
Bigger may be only slightly better
It's unfortunate that more people don't take a decent course in probability and statistics. That's why most folks are mystified by polls and can't understand why they work. They do work, as I've just shown you, within the limits of their accuracy. Pollsters can measure that accuracy and publish the limitations of their polls alongside their vote estimates. Every responsible pollster does this. (Naturally, everything I say is irrelevant when it comes to biased polls that are commissioned for the express purpose of misleading people. One should always treat skeptically any poll that comes directly from a candidate's own campaign staff.)
The controversy over sample size is constantly hyped by the statistically ignorant, most notably today by those who are upset by the sampling techniques used in a recently published Lancet study on civilian casualties in Iraq. (For example, here's the innumerate Tim Blair: “Remember: Lancet came up with this via a survey that identified precisely 547 deaths (as reported by the New York Times).” Mr. Blair thinks 547 is a tiny number.) More than forty years ago, Phyllis Schlafly was harping on the same point:
While her math is okay, Schlafly doesn't know what she's talking about. A sample size of 256 is quite good and should have produced a reliable snapshot of voter sentiment at the time the poll was conducted. In addition to getting the pollster's name wrong (it's Mervin), Schlafly neglected to mention that Rockefeller's wife had a baby just before the California primary, sharply reminding everyone about his controversial divorce from his first wife. You can't blame a poll for not anticipating a development like that. Otherwise, Schlafly's complaint about the poll is based on her ignorance about the sufficiency of sample sizes.The unscientific nature of the polls was revealed by Marvin [sic] D. Field, formerly with the Gallup poll and now head of one of the polls which picked Rockefeller to beat Goldwater in the California primary, who admitted to the press that he polled only 256 out of the 3,002,038 registered Republicans in California. He thus based his prediction on .000085 of Republican voters.

By the way, did you notice that Mervin Field's sample size was a power of 2? It would have occurred in the natural progression of samples that I modeled for you in our polling experiment. In my three different sampling examples, I doubled the sample size each time, going from 2 to 4 to 8, each time getting a significant increase in reliability. If you keep up the pattern, you get 16, 32, 64, 128, and 256. As you can see, Field went way beyond my little experiment, doubling my final sample of 8 an additional five times before he was satisfied he would be sampling enough voters for a good result.
Two caveats
There are a couple of things I should stress about the polling game we just played. First, of course, in real life we would not know the exact division of the voters beforehand. That's what we're trying to find out. It won't usually be something as nice and neat as fifty-fifty. However, as long as there's a real division between voters (in other words, not some 90% versus 10% rout), it won't be too difficult to poll enough voters to get an accurate profile.
Second, even a poll that is supposed to be within its estimated margin of error 95% of the time will be wrong and fall outside those bounds 5% of the time. That's one time in twenty. Therefore, whenever you see a political poll whose results seem way out of whack, it could be one of those flukes. Remember, polling is based on probability and statistics: it's accurate in the long run rather than in every specific instance. In a hot contest where lots of polls are taken, a candidate's campaign is likely to release only those polls that show the candidate in good shape. The 5% fluke factor may be just enough to keep hope alive among those people who believe everything they read.
Pollsters take their results with a grain of salt, so you should, too. But it's not because of sample size.









9 comments:
Thank you for the excellent explanation that I can now link to, Zeno. I have found myself trying to explain this same issue on several occasions, and I did not come out very persuasive.
This goes to support that probability and statistics (together with logic) should be taught to all kids from early grade school. Of course, in order to do that, we would first need to make sure the teachers understand it.
Great post! I remember when I was a young'un, I had a similar argument with my dad. He ended the argument by asking me "If you were doing blood analysis for a vet, why would you need a larger blood sample from an elephant than from a mosquito?" It took me quite a while of trying to counter that before I slowly realized that he was right.
Of course, the smaller your sample size, the harder you have to work to get a representative sample. That is a science (or art) in and of itself. In theory, a good representative sample should be better than a purely random sample (eg. you're less likely to accidently pick 8 subjects who all just returned from the Lexus dealer), but great care must be taken that your attempts to bias towards representationalism do not admit other biases that make your sample worse than a random drawing. A good poll will explain how they chose their sample.
I know I'm going off on a tangent here, but continuing on things that skew poll results (unlike sample size): framing the questions. Even a poll with a perfectly true representative sample can be made unrepresentative by misleading framing of the questions. Good polls publish exactly how their questions were asked. But this could be considered as part of the next type of abuse.
Misinterpretation of the data is probably the single worst way polls are misused. (eg. 80% [i'm making these numbers up] of Republican voters consider themselves "religious" therefore only 20% of religious voters will vote Democratic.) As long as the general public remains ignorant of basic probability and statistical theory, this kind of lying will be pervasive--and yes, that includes the sample size myth. [/rant]
ps --- I've always liked his triangle better than his wager.
Thanks for your comments, Science Pundit. Yes, getting representative samples is an interesting problem in its own right. That's why the Literary Digest so famously predicted an Alf Landon victory over Franklin D. Roosevelt despite their huge sample size: their respondents were drawn from lists of automobile and telephone owners. Guess how that skewed back in the 1930s!
To get concrete results to share with my readers, I had to make an assumption about the "real" breakdown of voter preference in the thought experiment. Fortunately, my arguments hold up very well in the cases that people really care about: close elections where voter sentiment is evenly divided. In more lopsided races you can still get good polling results (though who needs them?), but the sample size will need to be increased to compensate for the added difficulty of picking up voters in both camps. Figuring out how big a sample really needs to be in difficult cases is a job for professionals.
Good stuff Zeno, thanks.
I wonder how pollsters can factor in a year like 2006, in which the Democratic base is REALLY motivated, while the GOP base is much less likely to participate?
I know there are 'likely voter' models, but somehow I keep thinking that extraordinary motivation on one side can yield results that are outside the margins of the poll.
Excellent intro, and a much more engaging example than those silly coin tosses they're always maundering on about in basic statistics. When you feel like doing a second post in this vein (or maybe you already have? I haven't read the rest of your blog) attack the ignorance about confidence limits. Confidence limits show whether the sample size is big enough to represent the population. There's no need to wonder whether the sample was adequate, even if you're a Republican.
Very nice. Fir a little longer discussion, see this series of posts by Echidne.
Nicely done explanation. As a high school government teacher I teach a little polling. This should help me explain the statistics, etc to my students in an easy to understand way.
That's ironic about Phyllis Schlafly's deficiencies in math. Her son, Roger Schlafly is a mathematician (well, actually a mathematically oriented computer person) who successfully patented a prime number.
I came to this rather late, but I wanted to thank you for this clear, engaging, and well-illustrated demonstration of how polling works. I'll keep these examples in mind in case I ever need to explain something similar to a friend!
Post a Comment